Redefining Intelligent Document Processing
AIDP helps the world's largest enterprise brands better process their data - turning weeks into hours, eliminating manual workflows, and improving data accuracy beyond 90%




The Complete Workflow Solution
Go Beyond OCR with AIDP
AIDP brings together OCR, NLP, and AI to efficiently extract, process, and deliver first-mile data directly where it’s needed to accelerate business operations.
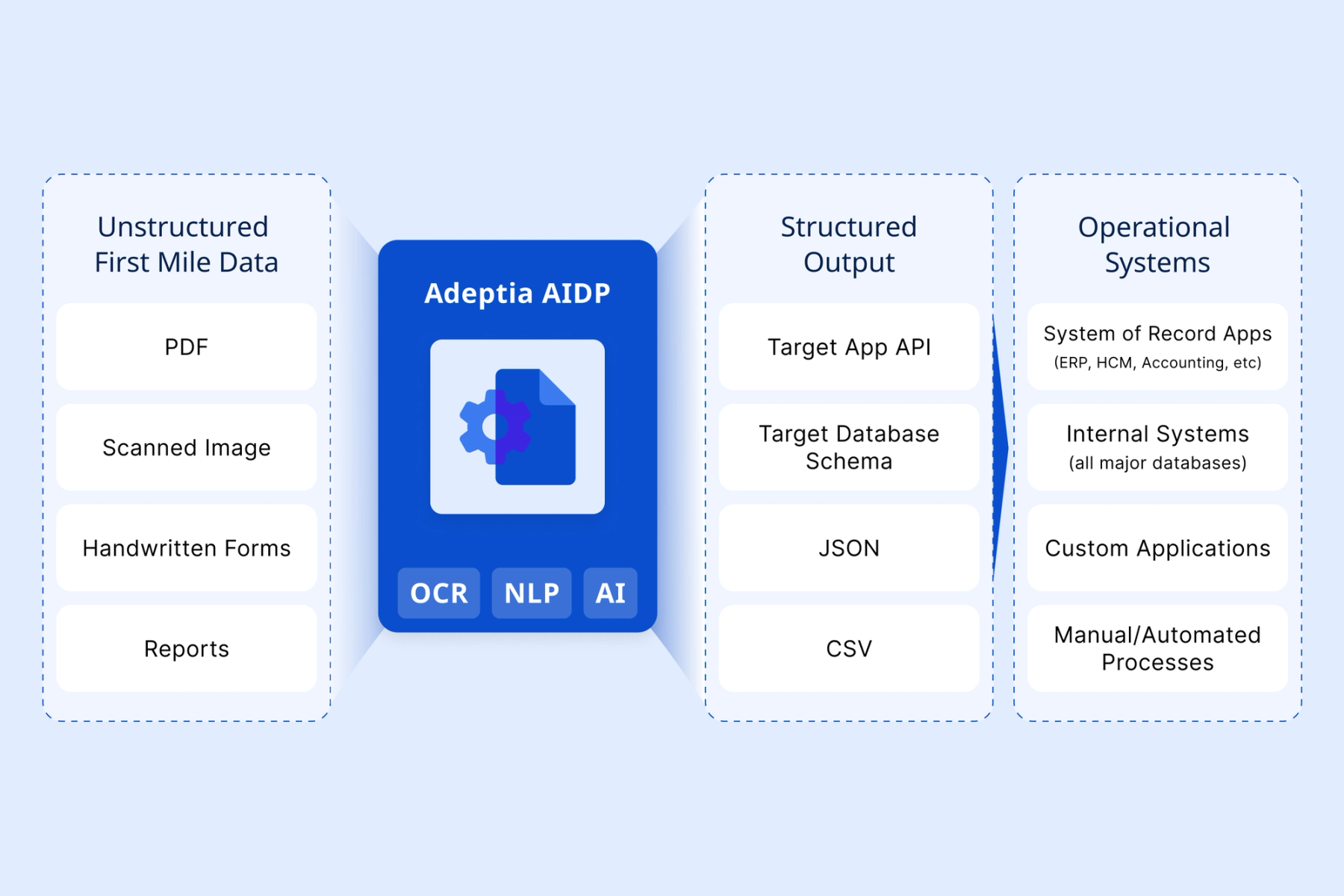
Make Informed, Data-Driven Decisions with AIDP
AIDP meets the large-scale performance requirements that enterprises need — with the control of manual processes and efficiency of AI solutions
- 99% Accuracy

We leverage Optical Character Recognition (OCR), Natural Language Processing (NLP), and Artificial Intelligence (AI) to efficiently extract and process data with over 99% accuracy
- Seamless Integration

Structure your data for downstream use or plug directly into enterprise applications with Adeptia’s Connector Library.
- Deployment Flexibility

Meet your data where it's at with cloud, on prem, or hybrid deployments.
Explore Adeptia Intelligent Document Processing
Automate your first-mile data™ ecosystem without limits to power intelligent business operations.
Flexible Deployment for Real-World Data Environments
Our AIDP was designed specifically to work within the complex constraints of regulated industries — hybrid, on-prem, AWS or Azure.
- Data Sovereignty
On-premise IDP solutions allow organizations to maintain control over their data, ensuring it remains within their infrastructure.
- Integration with Existing Systems
Deploying IDP on-premise facilitates seamless integration with legacy systems and workflows.
- Meet First Mile Data Where it’s At
First-mile data is often born in non-cloud settings: manufacturing plants, financial institutions, healthcare systems, and regulated supply chains.
Resources


