




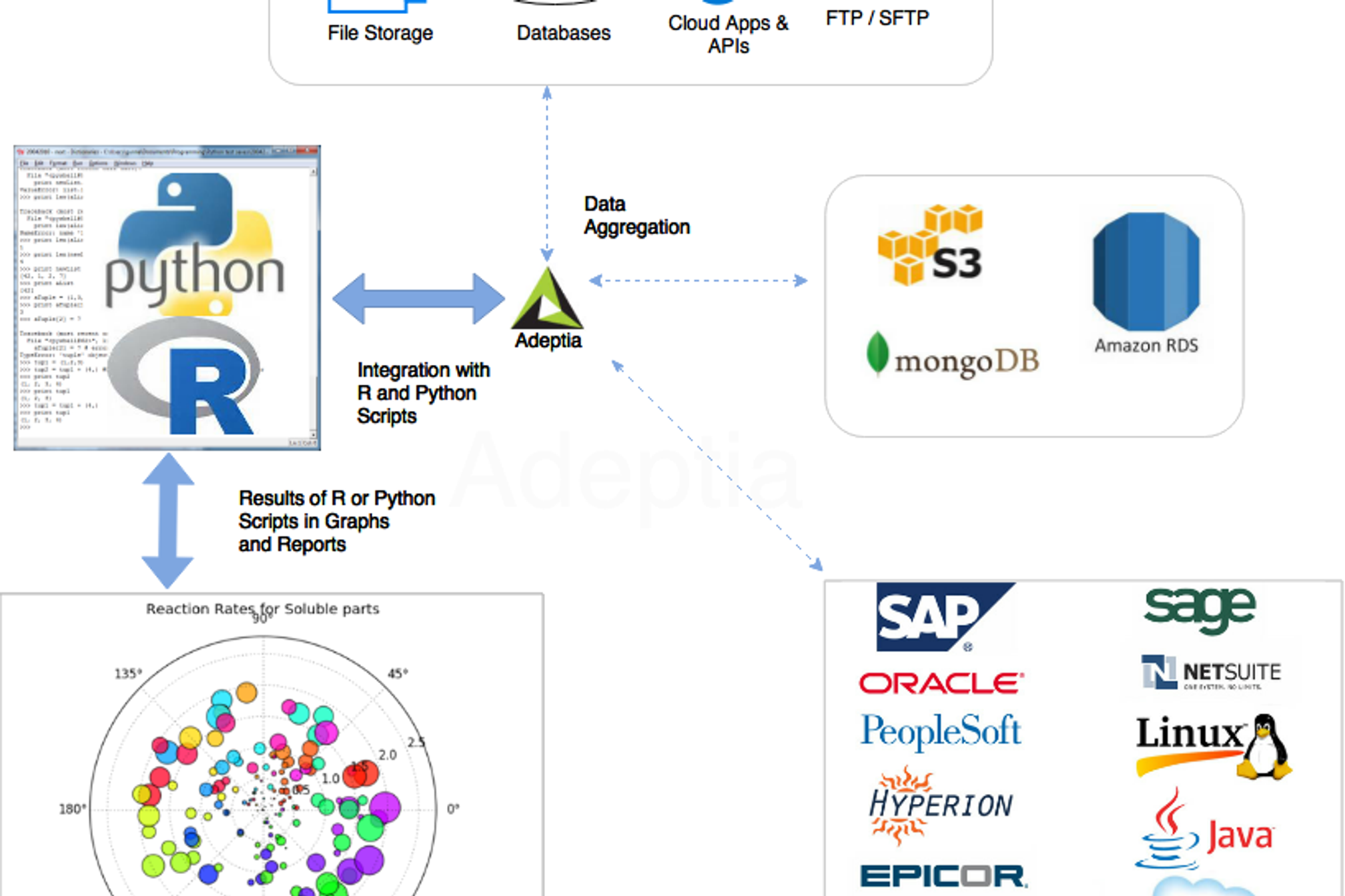
R and Python are popular programming languages used indata science. Data Scientists use these languages and build complex algorithms to run large amounts of data in order to gain insight into processes and systems. Results derived from these algorithms help in predictive analytics, statistics and data mining.
Adeptia provides data scientists with important features in automating three important steps in running R and Python programs:
- 1.Data preparation and aggregation of data from multiple systems
- 2.Integration of data into the R and Python programs
- 3.Execution of R and Python programs and distribution of results in the form of graphs and reports to data analysts
Adeptia is a browser-based application that allows Data Scientists to collaborate and design rules to aggregate data from multiple systems, map that data into a canonical format and ingest that data into R and Python scripts.
Let’s talk about these features in detail.
Data Preparation and Aggregation
Data Scientists need to aggregate data from disparate systems and prepare the data before ingesting it into their programs. Data may exist in files, in systems, or in cloud applications and the challenge is to connect to these entities, gather the data based on certain rules and consolidate this information in a standardized format that can be then used as an input to these programs. Adeptia provides connectors to easily gather this information from any system such as Databases, ERP/CRM systems, Procurement, SFTP, APIs and so on. Adeptia supports reading of data from EDI, EDIFACT, XML, JSON, ASCII, CSV, Excel, Text based PDF files, Fixed Width and many more.
(Figure: Adeptia Self-Service Integration for Data Scientists)
In regards to data preparation, Adeptia provides a graphical, drag-and-drop Mapper interface that can take any source format and convert the data into an output format needed by R or Python programs. Data Mapper interface opens from the browser and the end-user can map the elements to the target fields and validate the results of the data transformation. Data Scientists can create a standard map and reuse these maps on other data sources. Template maps help to accelerate data conversion setup as users can make a copy of a template and reuse most of the conversion rules for a new data source. Data can be in files, data warehouse or data marts, cloud applications or backend ERP systems and Adeptia can pull the information and make it available in the maps for the users to apply the conversion rules. Some of the rules can be related to setting up context variables that are needed as input fields to run the programs such as setting up variable values, file paths, pointers to a database table, endpoint to an API that would send a payload at runtime. And these variables can be dynamically passed to the programs so that the data can be pulled automatically at runtime by the scripts.
Here’s an example of Adeptia Data Mapper that graphically shows the source and target schemas and allow users to map the fields through a point and click interface. Adeptia’s Data Mapper allows conversion of multiple sources to targets in a single map.
(Figure: Adeptia’s graphical data mapper/data transformation interface)
Data Integration
Ingesting data into R and Python scripts is enabled through the process flow. Data Scientists can open up a Process Designer in Adeptia and draw out the multiple sources to target flows and add process rules to route and execute the data based on different runtime conditions. For example, in a use case for chemical engineering, users may want to run different algorithms to analyze the soluble rate of catalyzed particles or generate a spectral density graph of an element. Here based on the type of data being routed to the flow at runtime, the process determines which script to execute and passes the source data to the script.
Process Flows are available under the Process Designer Service page and users can click on an existing flow and make edits to the rules and add more steps in the flow. Users can create multiple flows that call different scripts and pass different types of converted data into those scripts. All flows are linked to version control and provide revision history of all the changes that have occurred in the flow over time.
(Figure: Adeptia Process Designer Manage Service page)
As part of the R and Python connector, Adeptia provides plugins that allow users to define the location of the scripts (such as python-java-bridge Anaconda folder) that are going to be executed. Adeptia can dynamically pass values to the declared variables and data paths initialized in the scripts.
(Figure: Example of a Plugin that initializes the Python script to be called and the data that needs to be analyzed)
Execution of R and Python programs
Executing R and Python scripts is automated through delivering the data into the location specified in the scripts or by providing the data location and variable values through a web form that triggers the scripts. Process Flows in Adeptia can be triggered via a web form. Other types of triggers include batch jobs, file or ftp events, process invocations through web services/APIs, message queues and email.
For example, we can configure a web form in Adeptia (as shown below) that allows users to specify some of the variable values needed in the scripts and the type of script that needs to be run. In this case, the script already has access to the data and the form input provides additional dynamic information to trigger the script. User can provide variable values and code that are executed by the script.
(Figure: Adeptia Web Form triggers a process flow and shows the results)
Results of R and Python scripts can also be delivered as Reports to the data analysts via email or through a dashboard. Business uses or data analysts can login to Adeptia and view the reports and can rerun the scripts with new data.