Blog•
What Is Intelligent Document Processing (IDP)?
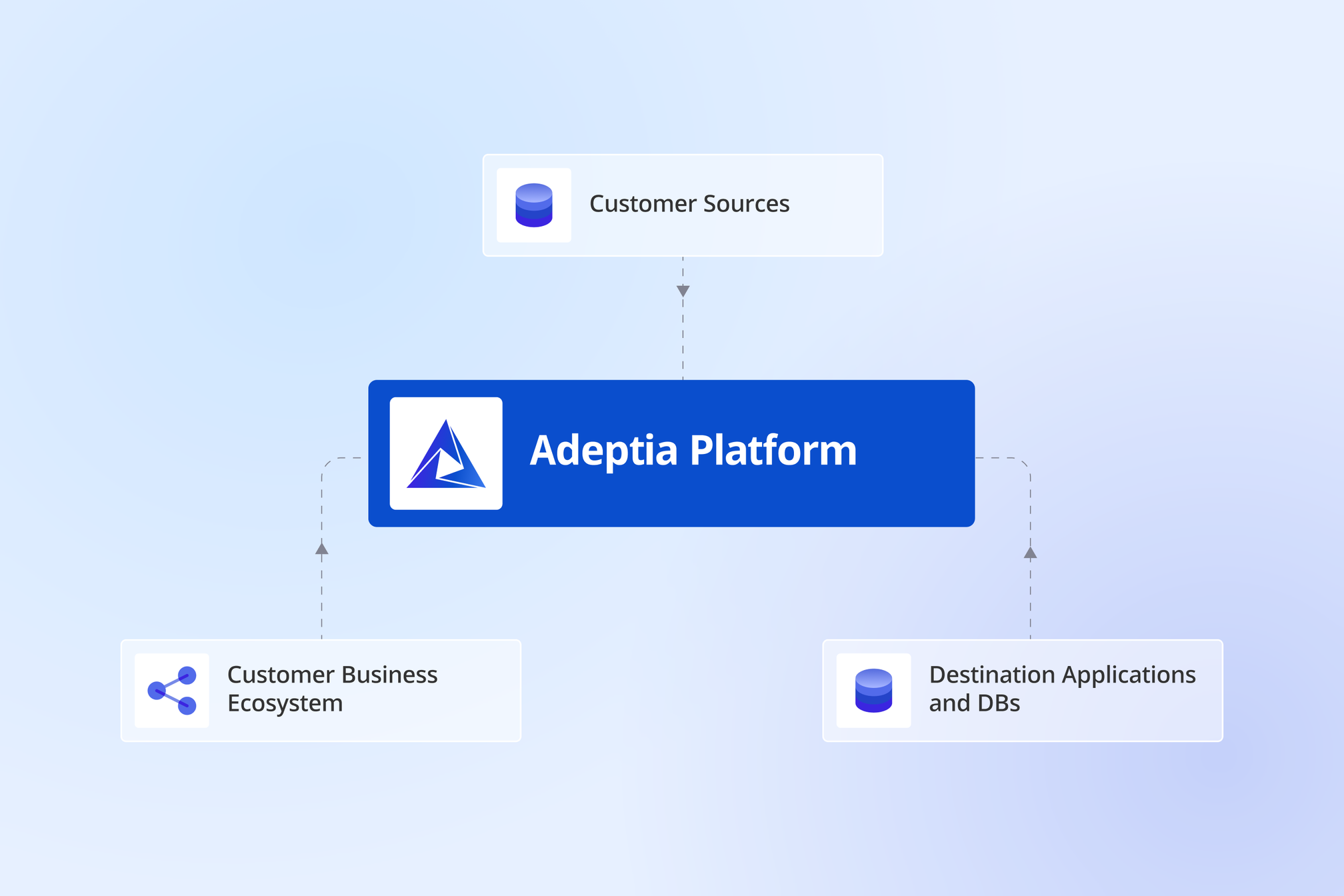
Over half of all enterprise data still arrives as a scan, fax, or paper form across invoices, claims, medical certifications, loan applications, customs declarations, enrollment paperwork, and more. T...

Adeptia