Blog•
Excel Paradox: Why Spreadsheets Remain Enterprise Data's Biggest Integration Challenge
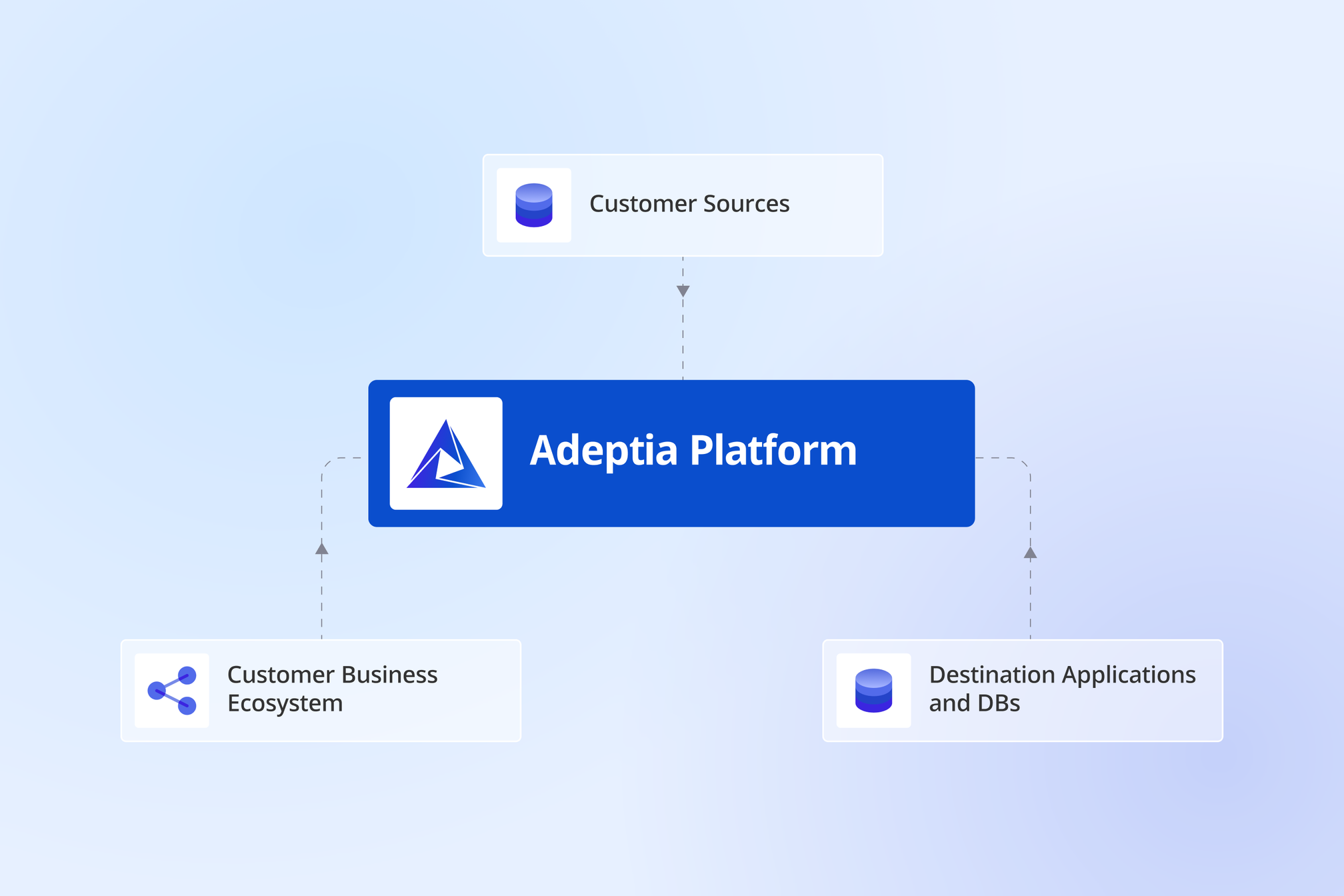
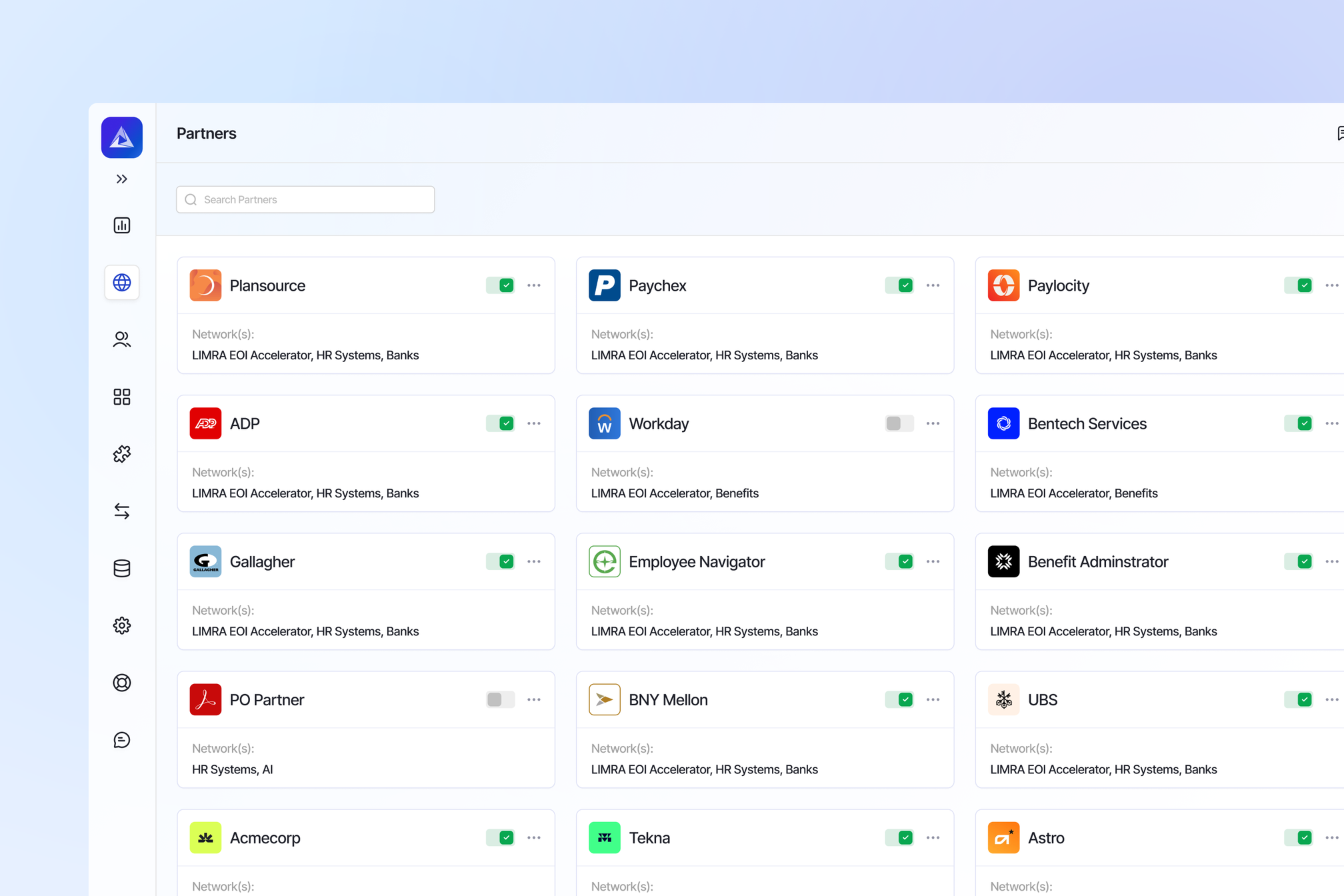
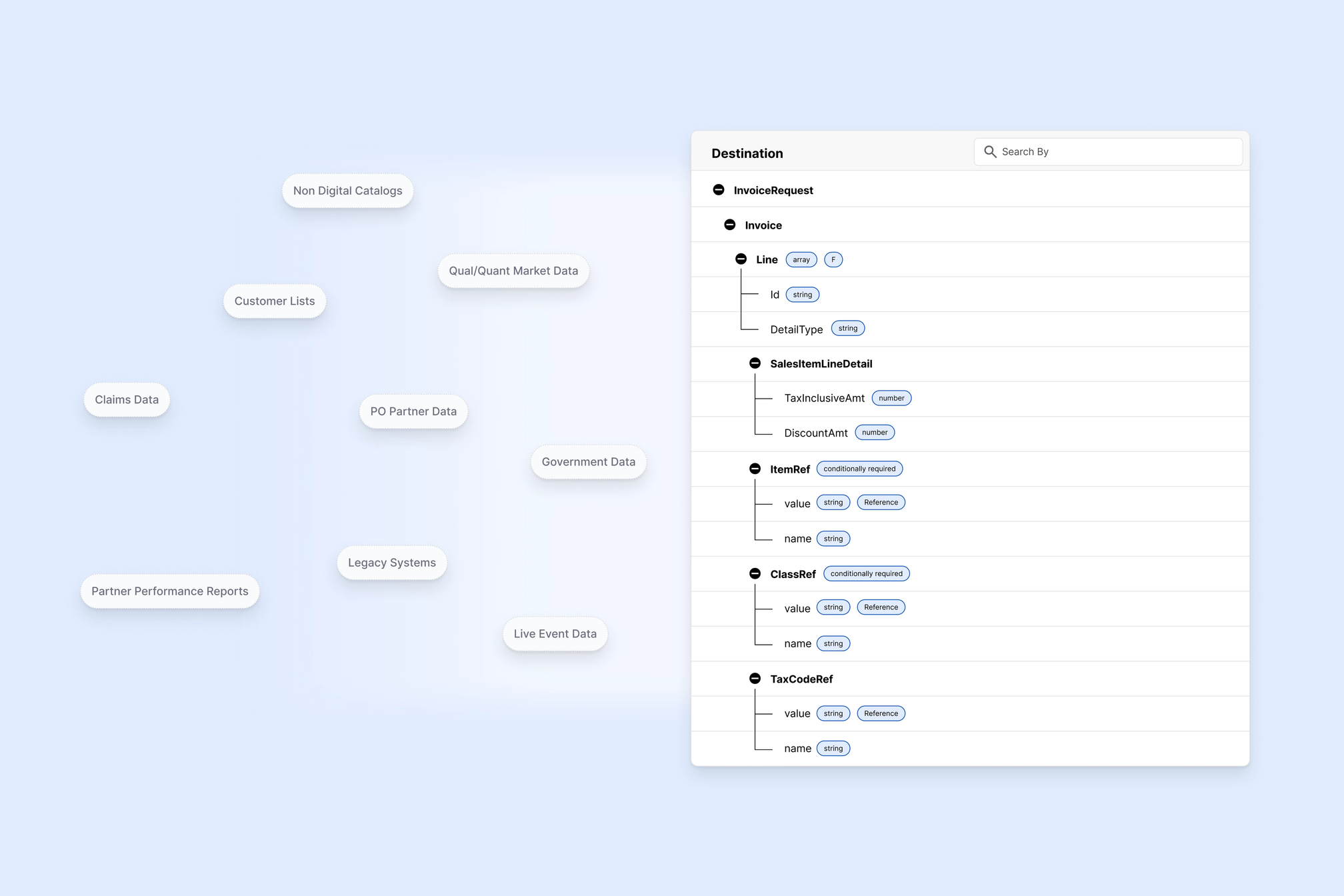
Every enterprise runs on data. Pricing, compliance, billing, customer experiences, partner coordination—all depend on data flowing smoothly across systems, teams, and business processes....

Deepak Singh